Contrastive Language-Image Pre-training (CLIP) has emerged as a simple yet effective way to train large-scale vision-language models. CLIP demonstrates impressive zero-shot classification and retrieval on diverse downstream tasks. However, to leverage its full potential, fine-tuning still appears to be necessary. Fine-tuning the entire CLIP model can be resource-intensive and unstable. Moreover, recent methods that aim to circumvent this need for fine-tuning still require access to images from the target distribution. In this paper, we pursue a different approach and explore the regime of training-free "name-only transfer" in which the only knowledge we possess about the downstream task comprises the names of downstream target categories. We propose a novel method, SuS-X, consisting of two key building blocks: SuS and TIP-X, that requires neither intensive fine-tuning nor costly labelled data. SuS-X achieves state-of-the-art zero-shot classification results on 19 benchmark datasets. We further show the utility of TIP-X in the training-free few-shot setting, where we again achieve state-of-the-art results over strong training-free baselines.
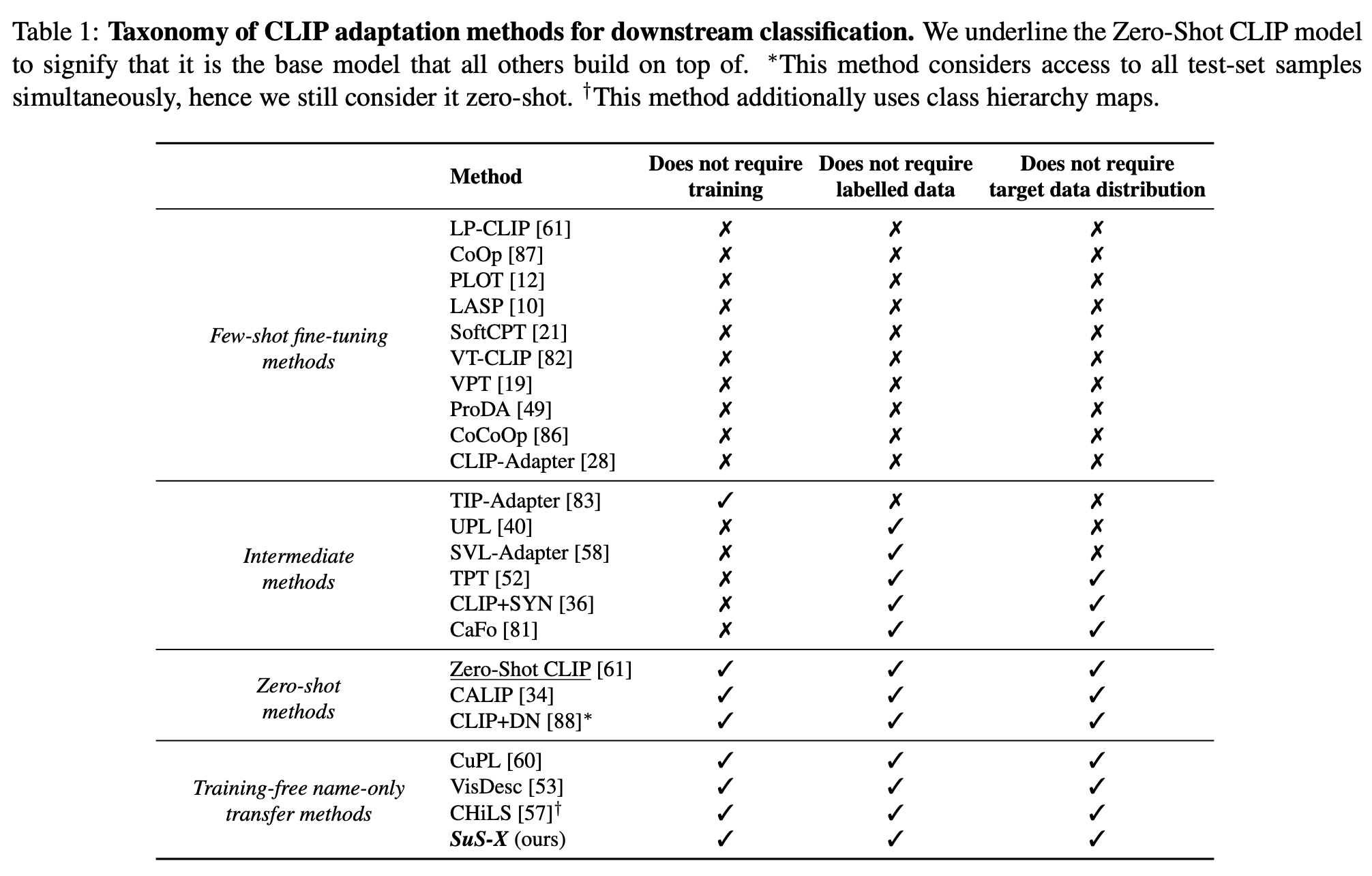
CLIP's zero-shot downstream classification performance is limited by its pre-training distribution: if the downstream dataset diverges too strongly from the distribution of images seen during pretraining, CLIP’s zeroshot performance drastically drops. Several works have tried to mitigate this problem , we characterise some of these methods along three major axes: (i) if the method requires training, (ii) if the method requires labelled samples from the target task, and (iii) if the method requires samples from the target task distribution.
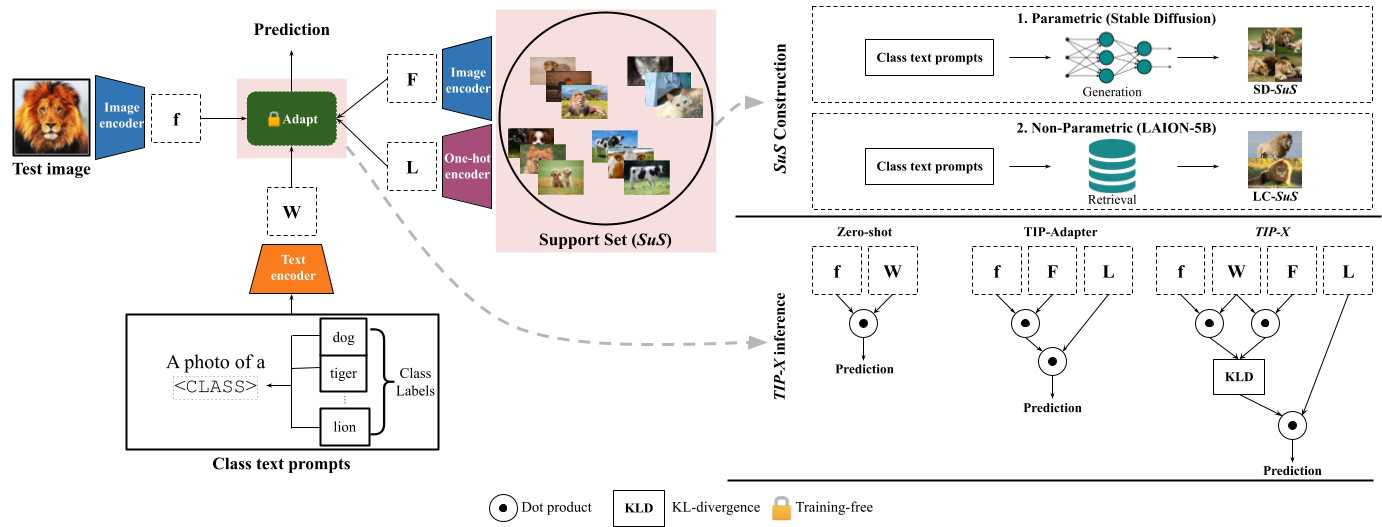
To curate a support set with no access to downstream image samples, we employ two strategies. For both these strategies, we use the class names of the downstream task and utilise better prompts from GPT-3.

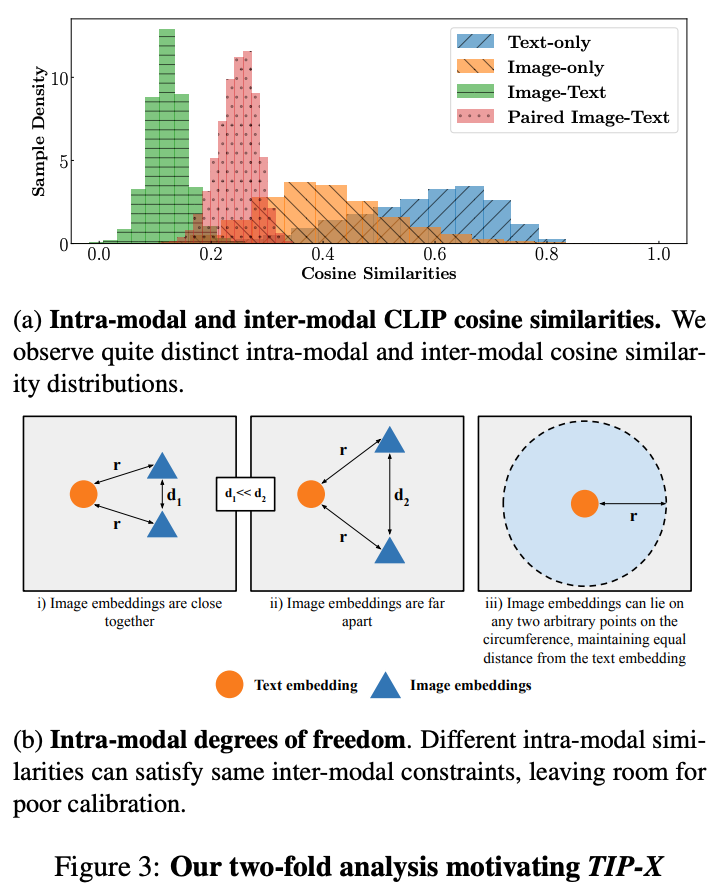
We observe that intra-modal and inter-modal similarities are distributed differently in the embedding spaces of VLMs like CLIP: the inter-modal similarities have small variance and mean, whereas the intra-modal similarities have larger means and variances. This mismatch happens because contrastive training of CLIP (and other VLMs) maximises the inter-modal cosine similarities of paired samples without regard to intra-modal similarities. Thus, prior methods that use intra-image CLIP embedding similarities do not reflect the true intra-image similarities. We propose a simple modification in the form of TIP-X where compute intra-image similarities by using the inter-modal similarities as a bridge instead.
Training-free name-only transfer: We beat competitive methods in the name-only transfer setting on 19 diverse datasets.
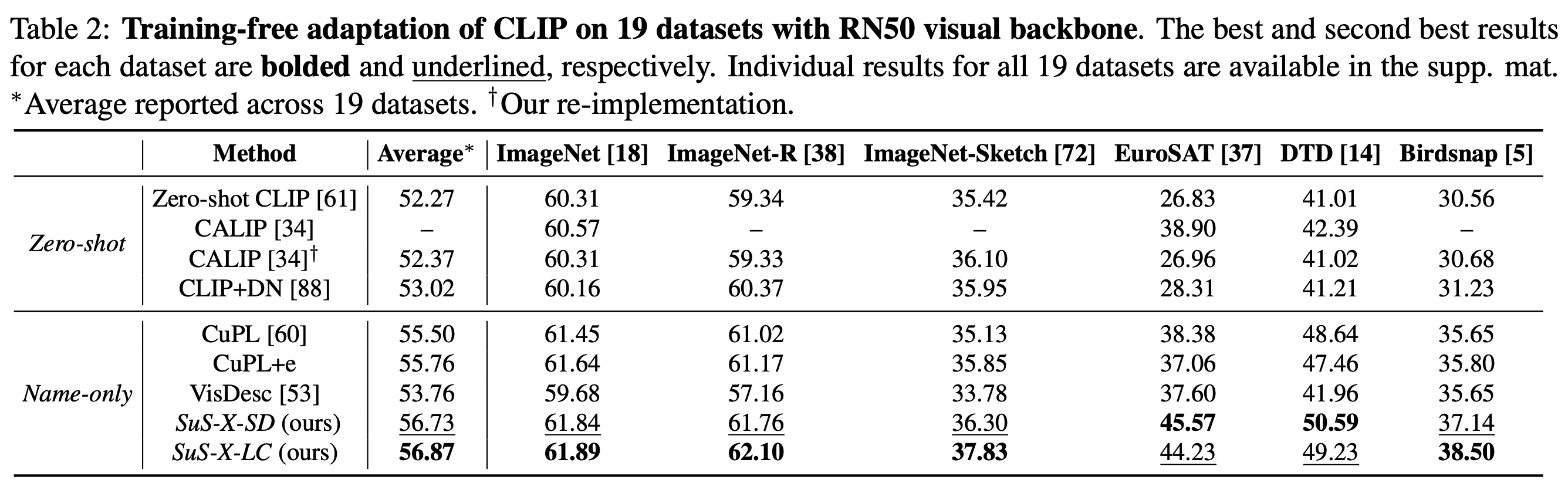
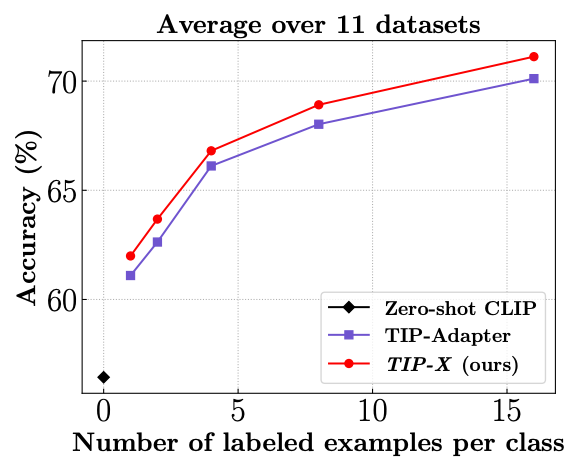
SoTA on training-free few-shot setting: We beat TIP-Adapter in the training-free setting on 19 diverse datasets.
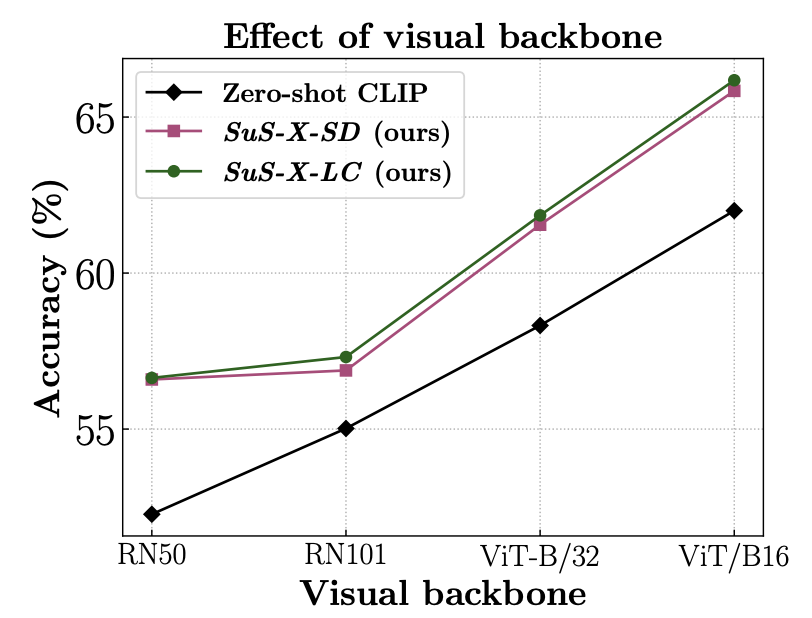
Generalisation to different CLIP visual backbones: Our method generalises and consistently improves performance across different CLIP visual backbones.
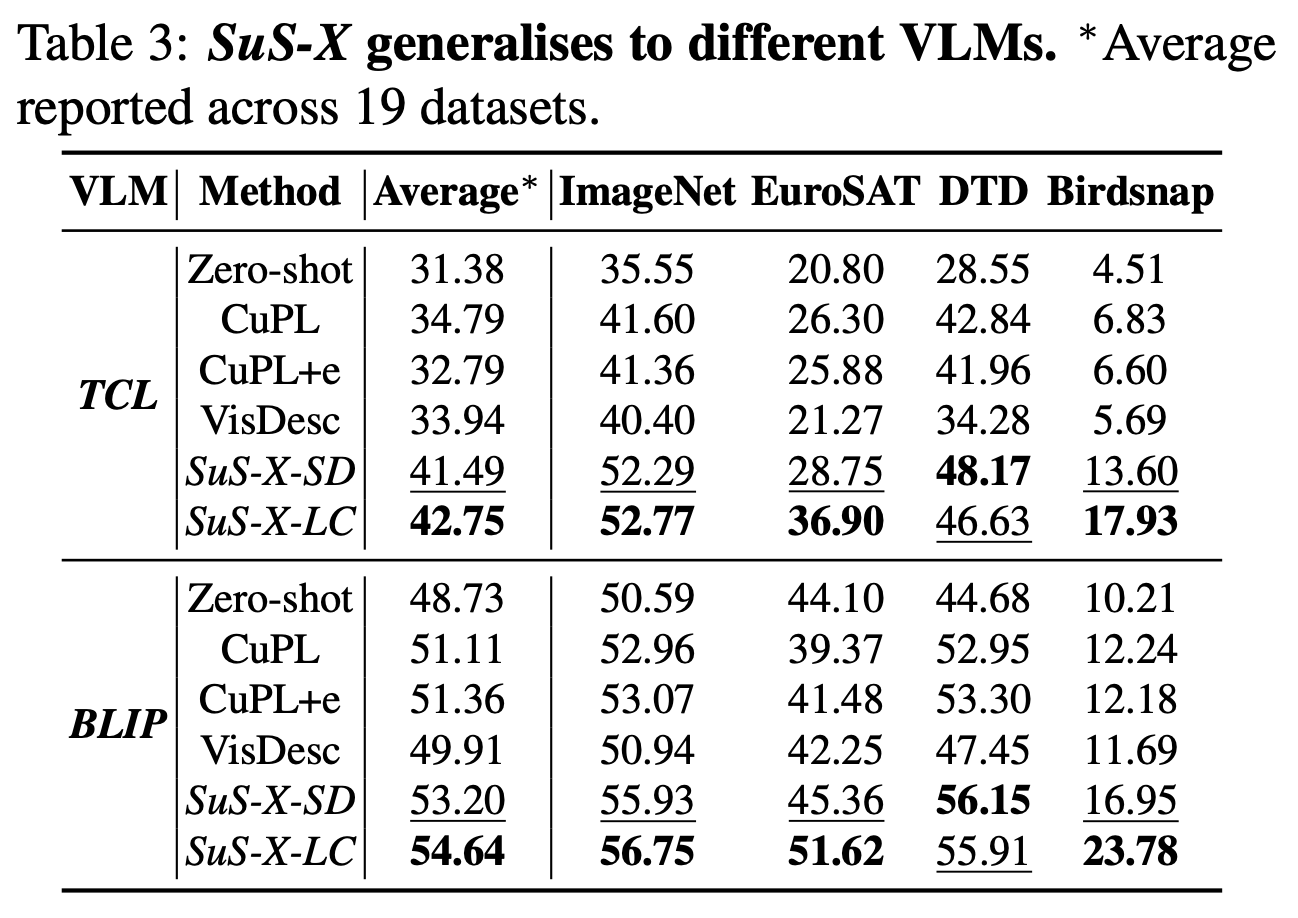
Generalisation to different VLMs: Our method generalises across different VLMs other than CLIP.
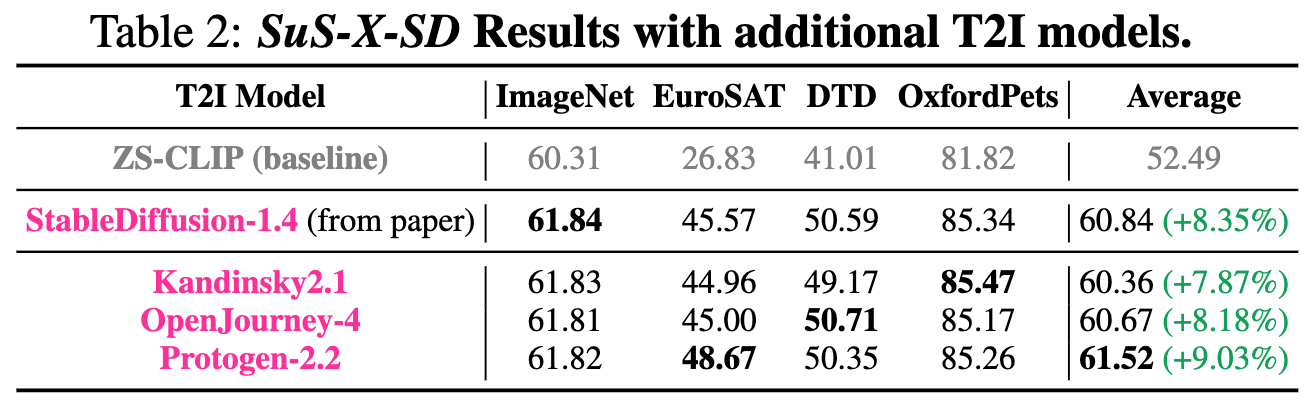
Generalisation to different T2I models for SuS-SD curation: Our method generalises across different T2I models used for
@article{udandarao2022sus,
title={Sus-x: Training-free name-only transfer of vision-language models},
author={Udandarao, Vishaal and Gupta, Ankush and Albanie, Samuel},
journal={arXiv preprint arXiv:2211.16198},
year={2022}
}